歐吼~昨天我們講完了CNN今天就接著來說RNN嚕
循環神經網絡(RNN)是一種深度學習模型,主要用於處理序列數據,像是文本、語音、時間序列等,它的獨特之處在於允許信息在不同時間步之間互相傳遞,因此能夠捕捉到序列數據中的時間相關性。
RNN的基本結構包含一個或多個時間步,每個時間步處理序列中的一個元素,例如處理句子中的每個詞語等等,以下是RNN的一些重點概念:
循環結構:RNN的結構是循環的,它允許信息在不同時間步之間進行反饋,這代表模型在處理序列時可以保持記憶,並根據過去的輸入做出決策。
隱藏狀態:RNN在每個時間步都有一個隱藏狀態,這個狀態包含了過去時間步的信息,可以把它看作是模型內部的記憶,用來捕捉序列的上下文和時間相關性。
權重共享:RNN的不同時間步共享相同的權重,因此模型學習到的參數在整個序列中都是一致的。
這裡放上一張示意圖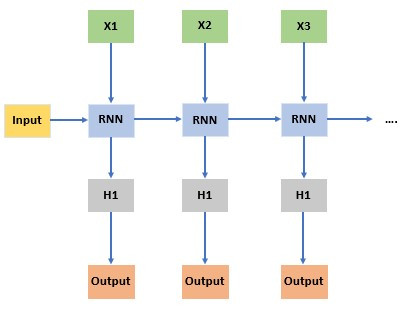
X1、X2、X3 表輸入數據序列的不同時間步。
RNN代表 RNN 單元,每個時間步都有一個。
H1、H2、H3 代表 RNN 單元在不同時間步生成的隱藏狀態。
Input 代表模型的輸入層,接收來自 X1、X2、X3 的輸入數據。
Output 代表模型的輸出層,產生預測或其他結果。
箭頭表示了數據的流動方向,輸入 X1、X2、X3 進入輸入層,然後通過 RNN 單元在每個時間步處理,生成相應的隱藏狀態 H1、H2、H3。模型的輸出可以基於這些隱藏狀態或者其他計算而產生。
這是簡化版 RNN 結構示意圖,RNN 還可以有更多的層和其他變體,但這個示意圖可以幫助你理解整體結構概念。
RNN通過反向傳播算法進行訓練,目標是最小化某種損失函數,使模型能夠預測序列中的下一個元素或執行其他序列相關任務,同時可以堆疊多個RNN層以增加模型的複雜性,這形成了深度循環神經網絡(Deep RNN)。
同時因為RNN存在梯度消失問題,為了解決這個問題出現了一些變種模型,如長短期記憶網絡(LSTM)和門控循環單元(GRU),它們引入了特殊的門控機制,以改進信息的傳遞和記憶能力。
RNN在多個領域有廣泛應用,包括自然語言處理、語音識別、時間序列預測等。然而它也存在一些問題,例如長期依賴性的建模和梯度消失問題(還會因時間久了前面輸入經計算過程逐漸被淡化)。為了應對這些問題,研究人員開發了更高級的模型,如LSTM和GRU這些模型在處理序列數據時有更好的表現。
以上就是對於RNN的大致介紹,下面一樣讓我們來進入實作環節。
這段程式碼是用於建立、訓練和評估一個簡單的RNN模型,下面我們會做情感分類任務,該任務是將IMDB電影評論分為正面和負面兩類。以下是對這段程式碼的詳細解釋
import tensorflow as tf
from tensorflow.keras.datasets import imdb
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, SimpleRNN, Dense
from tensorflow.keras.callbacks import EarlyStopping
import matplotlib.pyplot as plt
num_words = 10000 # 使用前10000個常見詞彙
maxlen = 200 # 截斷或填充評論的最大長度
embedding_dim = 64 # 嵌入層的維度
rnn_units = 32 # RNN隱層的維度
定義模型的結構和訓練過程。
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=num_words)
x_train = pad_sequences(x_train, maxlen=maxlen)
x_test = pad_sequences(x_test, maxlen=maxlen)
這裡載入了IMDB數據集,並使用pad_sequences函數將序列填充或截斷為相同的長度,以確保它們具有相同的維度。
第一次應該會跑出下載畫面
model = Sequential()
model.add(Embedding(input_dim=num_words, output_dim=embedding_dim, input_length=maxlen))
model.add(SimpleRNN(units=rnn_units, activation='relu'))
model.add(Dense(units=1, activation='sigmoid'))
這裡建立了一個序列模型,包括嵌入層、SimpleRNN層和全連接層,嵌入層將整數索引轉換為密集向量表示,SimpleRNN層用於處理序列數據,全連接層用於二元分類(正面或負面情感)。
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
early_stopping = EarlyStopping(monitor='val_loss', patience=3, restore_best_weights=True)
在這裡老樣子選擇了優化器(adam)、損失函數(binary_crossentropy)和準確率(accuracy),還有上次所使用的early_stopping。
history = model.fit(x_train, y_train, epochs=10, batch_size=128, validation_split=0.2, callbacks=[early_stopping])
模型將訓練10個epoch,每個batch的大小為128,並使用前面定義的EarlyStopping回調函數。
test_loss, test_accuracy = model.evaluate(x_test, y_test)
print(f"測試準確率: {test_accuracy*100:.2f}%")
顯示準確率
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
最後一樣使用Matplotlib繪製了訓練和測試集的損失曲線。
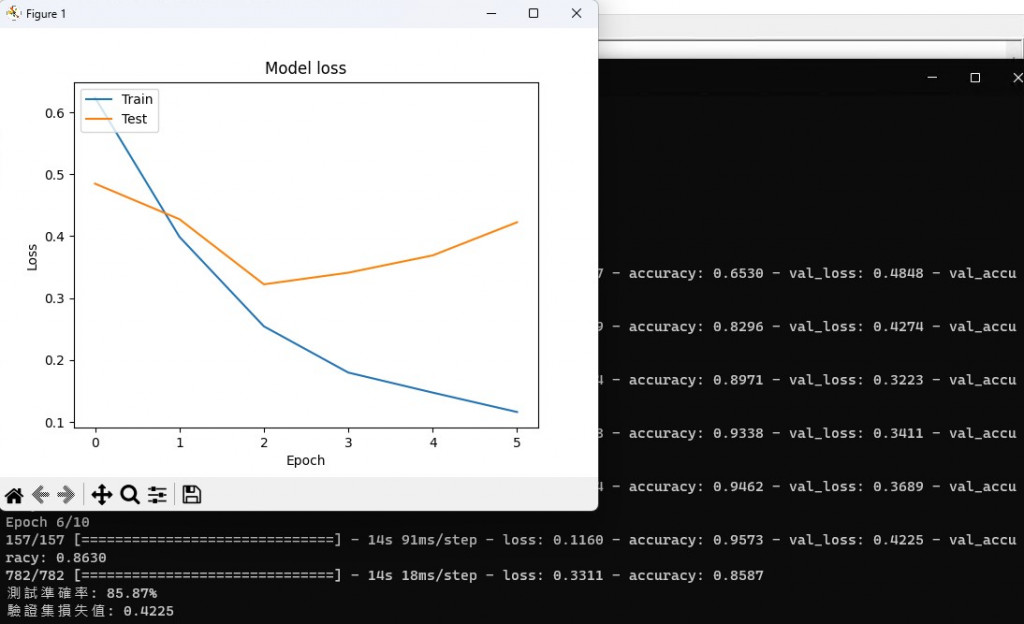
那麼以上就是今天的RNN模型,希望有幫助到你一點,中間有提到RNN的一些缺點,也說到因缺點而誕生變種LSTM,明天我們就以LSTM來做介紹,來了解他與純RNN的不同,並且我們明天讓我們的輸出視覺化一點,單純跑出準確率與Loss是不是太過無聊了,那今天就先到這邊,我們明天見~~


